
Hot-code reloading on macOS/arm64 with Zig
Hot-code reloading, or hot-code swapping, is the ability of the compiler to allow you, the developer, to make changes to your program appear instantaneously while the program is already running. Typically, compilers utilise the idea of dynamic library hot swapping (for native targets such as macOS) where your program (logic) is compiled and linked down to a dynamic library (shared object) which is then managed and reloaded by a small loader program running side-by-side 1. Note that both programs, the dynamic library and the loader, do not share the same address space.
In Zig 2, we would like to try something else. Instead of having your program managed by a running side-by-side loader program, what if the compiler would “simply” update the memory of the running process? You will most inevitably think I have gone completely crazy, which given the current state of global affairs is not unthinkable, but hear me out.
Here’s my claim. We can pull it off using the self-hosted Zig compiler (also known as stage2 compiler). We can pull it off on Linux 3 and macOS (Windows coming soon TM), and here’s how. The self-hosted Zig compiler is a little bit special since it couples very tighly with our in-house linker 4. This gives it special powers which effectively mean we can completely bypass the idea of creating relocatable object files for Zig modules in favour of writing the already-relocated declarations/symbols directly into the final binary. I will refer to this concept as incremental compilation but some prefer to call it in-place binary patching, or incremental linking. Either way, the point is, the compiler does not generate any intermediate relocatable object files.
From incremental compilation…
Hmm, OK, Jakub, whatever you mean. How about an example to illustrate what you mean? Sure thing, just one more sentence of explanation before we dive into the problem of incremental compilation. The granularity at which the compiler works is scoped down to single declaration, aka decl or simply symbol, which is then incrementally allocated space in the virtual memory and a file offset, and written to the binary file (there’s a couple more things that actually happen here such as resolving relocations, if any, but you get the point). This allows us to update only those symbols that actually changed in an incremental fashion.
OK, example time! Consider the following Zig code
// example.zig
pub fn main() void {
var x: u32 = 1;
_ = bar(); // This is so that we force the compiler to generate bar before addToBar in the address space.
const y = addToBar(x);
assert(y == 11);
}
fn addToBar(x: u32) u32 {
const y = bar();
return x + y;
}
fn bar() u32 {
return 10;
}
fn assert(ok: bool) void {
if (!ok) unreachable;
}
In order to put Zig into incremental compilation mode, we will use a special flag --watch like so
$ zig build-exe example.zig --watch
(zig)
By this point, the compiler created a fully functional binary that we can run from disk. However, since
--watch flag puts the compiler in the REPL mode, we can update-and-run directly from the REPL loop
(zig) update-and-run
(zig)
In this case, no output is good news as this means we didn’t hit the assert. Let’s tweak the assert to something false though just to test that everything is working as expected
// ...
assert(y == 12);
// ...
and then retry update-and-run in the REPL
(zig) update-and-run
warning: process aborted abnormally
(zig)
Hmm, right, so assertion was correctly triggered in this case, and the compiler reported that the binary did not exit cleanly, just as we expected.
OK, but how any of this lend itself towards hot-code reloading in Zig? Right, let’s do another tweak to the
source where we change the definition of bar to something longer so that the linker will be forced to move
the symbol to a new location in the file and virtual memory
fn bar() u32 {
assert(true);
assert(true);
assert(true);
assert(true);
return 10;
}
Let’s update-and-run
(zig) update-and-run
(zig)
So far so good. If we now analyse the before and after of the update-and-run step, we will note that bar was moved
from its initial address in virtual memory of 0x1000010c0 to 0x100001178 since it grew too big to be accomodated
in its original place. I will stop here for a second and pull up a “printout” from a debugging tool 5 I wrote to
aid in visualising changes to the binary between incremental updates

There are two columns in the picture: the left hand side depicts the contents of the virtual memory before the next
incremental update, and the right hand side depicts the contents after the incremental update. I have purposefully
highlighted the symbol bar which, as predicted, has been moved in memory from 0x1000010c0 to 0x100001178
since it grew too big to fit its current placeholder (NB Zig’s incremental MachO linker does insert some
padding between symbols so that they can grow without necessitating the move, however in this case, we purposefully
grew the contents of bar enough to trigger the move and reallocation in virtual memory).
But what about any caller of bar? Did any symbol calling bar need a full rewrite? The short answer is no. Why,
you ask? Let’s pull up another view of the changes to the virtual memory contents of the file between updates, and
in particular, let us zoom in on addToBar
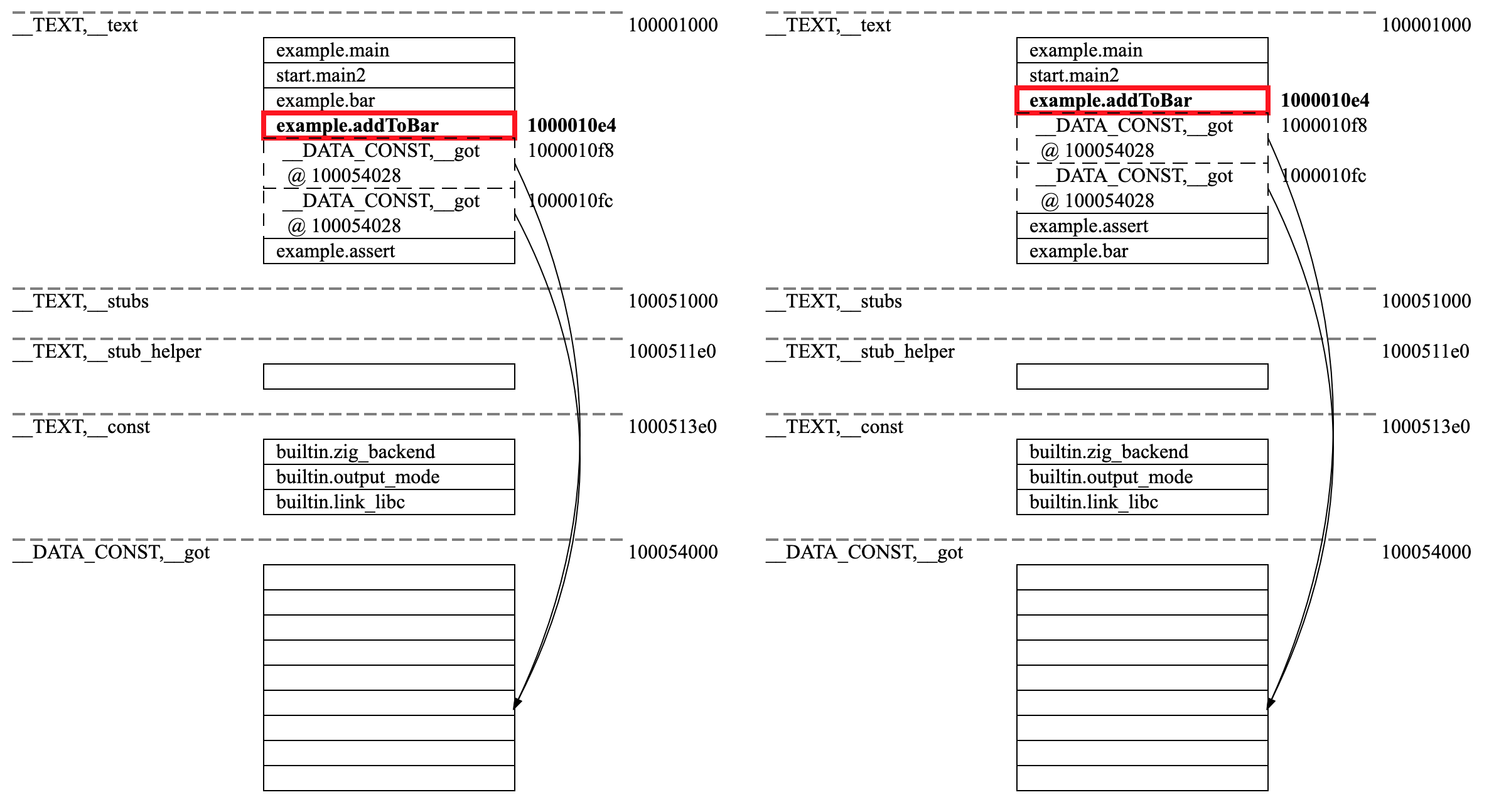
The contents of the highlighted addToBar depicts any relocation to any other symbol within the binary image.
Note that addToBar doesn’t make a direct reference to bar; instead, it references a mysterious cell in the
global offset table (GOT) denoted here as section __DATA_CONST,__got. The cell is located at an address 0x100054028.
Let’s pull up its contents in both views
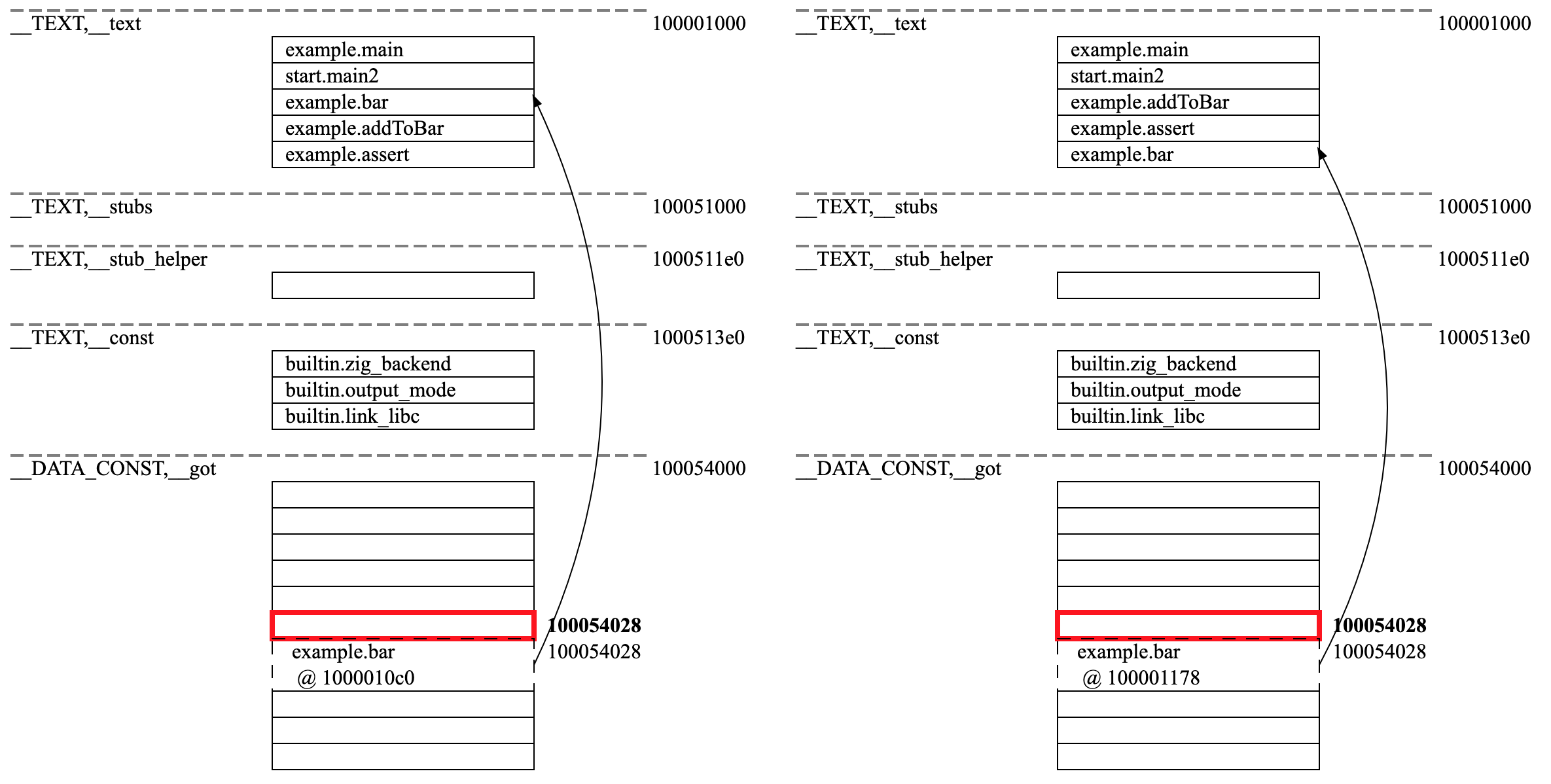
Note that both cells in both views still point to bar but the cell on the left hand side points to bar
at its original address of 0x1000010c0, while the cell on the right hand side to its new address after the move,
0x100001178. In other words, in order to preserve the integrity of the calls, all the linker had to tweak
was to update the target address of bar in its GOT cell. There was no need to touch any other symbol which
called bar as every reference to it is done via the GOT table. This mechanism lends itself really well
to hot-code reloading as it minimises the number of changes the linker has to do to the binary, and it will
be the cornerstone for our hot-code reloading solution. Let’s get right to it then!
…to hot-code reloading…
Before we go on, I will point out that in the rest of this post, I will mainly focus on Mach and macOS specific bits to get the ball rolling with respect to hot-code reloading with the Zig compiler. One additional bit required to actually get it all pieced together into a working solution is to roll out some mechanism for communicating with the compiler while in the hot-code reloading mode as communicating via stdio will be unavailable as we will be piping the output of the hot-code reloaded child process (our binary) via the compiler. Therefore, one could for instance communicate via a socket, and this is precisely how both Andrew Kelley 3 has done in his Linux proof-of-concept and I have done in my macOS proof-of-concept. Anyhow, in what follows, I will assume we already have the necessary infrastructure to do this.
I should also mention that if you would like to browse, and more importantly, play with a working version of the Zig compiler with hot-code reloading enabled on macOS, you can find the relevant source code in
hcs-macosbranch in the main Zig’s repo on GitHub 6.
First things first, we need to turn off address space layout randomisation (ASLR) for the child process (NB this is
actually not true, and we can successfully perform hot-code reloading with ASLR on. If you’re interested in this
bit, scroll down to the next section). On macOS, to do this from the user space, we need to utilise the posix_spawn
family of functions for spawning and executing a child process. In particular, we are interested in this function
int
posix_spawnp(pid_t *restrict, const char *restrict file, const posix_spawn_file_actions_t *file_actions,
const posix_spawnattr_t *restrict attrp, char *const argv[restrict], char *const envp[restrict]);
In order to request ASLR off from the OS, we need to pass an attribute object posix_spawnattr_t with
flags containing _POSIX_SPAWN_DISABLE_ASLR = 0x100. In Zig, I have made sure there are nice wrappers for
this, so all we need to do is
const std = @import("std");
const darwin = std.os.darwin;
const posix_spawn = std.os.posix_spawn;
// ...
var attr = try posix_spawn.Attr.init();
defer attr.deinit();
const flags: u16 = darwin.POSIX_SPAWN_SETSIGDEF | darwin.POSIX_SPAWN_SETSIGMASK | darwin._POSIX_SPAWN_DISABLE_ASLR;
try attr.set(flags);
const pid = try posix_spawnp(exe_path, null, attr, null, null);
(NB actually, since a few days ago, you don’t even need to use the posix_spawn
primitives at all, as spawning a child process on macOS will by default use this mechanism for you.)
And that’s it, the child process will now be put at its static addressing (if possible of course).
Having spawned the process and obtained its PID, we can now use it to open a Mach port to the child process which we can then use to update the child process’ memory, inquire about the base address where it was mapped to, etc. In order to open the Mach port, we need to use this Mach kernel function
kern_return_t
task_for_pid(mach_port_name_t target_tport, pid_t pid, mach_port_name_t *t);
The first argument is the Mach port handle for the parent process, and it can be obtained via an extern global variable
extern mach_port_t mach_task_self_;
the middle argument is the PID of the spawned child process, and the final argument is the receiver for the handle
to the opened Mach port. There is one caveat to using this (very) low-level API: it requires elevated privileges. This
is fine for the purposes of our proof-of-concept but definitely a no-go for production use of hot-code reloading mode.
One way of overcoming this, although please note I haven’t done a lot of investigation on it yet, is to bake in
the necessary entitlements into the compiler binary itself 7. To the best of my knowledge, this is how LLVM’s
lldb does it too. On the topic of debuggers, I am not sure if you noticed yet, but the hot-code reloading approach
I describe here is a close cousin of how debuggers work, and if you are curious about how different bits come together,
I invite you to study lldb’s source code which is openly available 8.
As with posix_spawn, I have created a couple of wrappers around Mach ports, and so the above process boils down to
const std = @import("std");
const darwin = std.os.darwin;
var task = try darwin.machTaskForPid(pid);
Having obtained a handle to the Mach port for communicating with the child process, we can now turn to where the actual magic is happening: the linker. Whenever the linker is requested to perform in-place binary patching as we analysed in the first section of this blog post, while writing the updated symbol to file, we use the obtained Mach port to at the same time write the updated contents directly to mapped memory of the running process. We need to be careful though, as writing to the executable segment will generally fail unless we purposefully change the current protection attributes of the segment. Thus, the approach is as follows:
check if the segment is writable
if yes, simply write to it an offset
if not
temporarily set the protection attributes to allow writing to it
write to the segment at an offset
reset the protection attributes to their original level
Since we control the linker, we do not have to actively check if the segment is writable as we control its protection attributes. In order to change the mapped segment’s attributes, we need to use the kernel function
kern_return_t
mach_vm_protect(vm_map_t target_task, mach_vm_address_t address, mach_vm_size_t size,
boolean_t set_maximum, vm_prot_t new_protection);
As before, Zig features nice abstraction for this, so this can be done as follows using the obtained task via
machTaskForPid(pid: pid_t) MachError!MachTask
try task.setCurrProtection(addr, len, std.c.PROT.READ | std.c.PROT.WRITE | std.c.PROT.COPY);
Notice the funky looking protection flag std.c.PROT.COPY = @as(vm_prot_t, 0x10) which is defined as VM_PROT_COPY
in Apple’s libc. According to the definition, this flag can be used to force request write permissions on a mapped
entry. Setting this flag marks the mapped entry as “needing copy” and effectively copying the object using copy-on-write
mechanics, and adding VM_PROT_WRITE permission to the maximum protections for the associated entry (NB an apt reader
might wonder why bother with updating the protection if we control the linker and can set the segment’s initial
and maximum protection attributes to be writable. Well, as it turns out, on arm64 macOS, the VM_PROT_WRITE protection
permission is not respected for the executable segment, therefore, there is no other way of achieving this than with
the use of VM_PROT_COPY flag.).
Writing into a mapped memory region is fairly straightforward, and can be achieved with the following kernel function
kern_return_t
mach_vm_write(vm_map_t target_task, mach_vm_address_t address, vm_offset_t data, mach_msg_type_number_t data_cnt);
In Zig, this becomes
const nwritten = try task.writeMem(addr, &buf, .aarch64);
Putting it all together, we got a routine that looks more or less like this
const sym: nlist_64 = //...
var buf: [LEN]u8 = //...
if (!seg.isWriteable()) {
try task.setCurrProtection(sym.n_value, &buf, .aarch64);
}
defer if (!seg.isWriteable()) {
task.setCurrProtection(sym.n_value, &buf, .aarch64) catch {};
}
// Here, we would resolve relocations (if any)
try resolveRelocs(sym.n_value);
const nwritten = try task.writeMem(sym.n_value, &buf, .aarch64);
That’s pretty much it!
Now here’s an exciting bonus question: can this be done without disabling ASLR? The answer is yes!
…with ASLR on!
I mean, if the debuggers can do it, so can we, right? With the ASLR back in the picture, we need to issue an additional kernel call to inquire about the base address for the mapped binary image. To do this, we need the following function
kern_return_t
mach_vm_region_recurse(vm_map_t target_task, mach_vm_address_t *address, mach_vm_size_t *size,
natural_t *nesting_depth, vm_region_recurse_info_t info, mach_msg_type_number_t *info_cnt);
Note that the variable address is passed by pointer. This is because after the call completes, address will receive
the value of the base address for the mapped image. We will then use this value to calculate the required slide
value for each non-PC-relative relocation. In other words, with this we are effectively turning our linker into
a dynamic linker!
Taking our snippet from above, we will end up with something like this
const pagezero_vmsize: u64 = 0x100000000;
const sym: nlist_64 = //...
var buf: [LEN]u8 = //...
const slide: u64 = slide: {
const info = try task.getRegionSubmapInfo(sym.n_value, buf.len, 0, .short);
const slide = info.base_addr - pagezero_vmsize;
break :slide slide;
};
if (!seg.isWriteable()) {
try task.setCurrProtection(sym.n_value + slide, &buf, .aarch64);
}
defer if (!seg.isWriteable()) {
task.setCurrProtection(sym.n_value + slide, &buf, .aarch64) catch {};
}
// Here, we would resolve relocations (if any)
// For any non-PC-relative pointer value, resolve and slide
try resolveRelocs(sym.n_value, slide);
const nwritten = try task.writeMem(sym.n_value + slide, &buf, .aarch64);
Note that we subtract the size of __PAGEZERO segment from the returned base address to get the slide value. Then,
for any relocation that is non-PC-relative and is a pointer, we relocate the pointer value and add the slide value.
This is equivalent to what dyld would do for all rebase opcodes encoded as part of the “rebase info” subsection of
LC_DYLD_INFO_ONLY load command.
Demo!
Demo captured on M1 MacBook Air, macOS 12.2.1, latest Zig self-hosted compiler with patch from hcs-macos branch. 6